Strategies for Test Data Preparation
Financial Products Subledger
Strategies for Test Data Preparation
Financial Products Subledger
Introduction
Customers spend a lot of time on testing during a software implementation project. From early prototyping to unit testing, system testing, integration testing, performance testing, user acceptance testing, and, of course, continuous regression testing if anything has changed.
The prevalence of testing throughout all phases of a project should make it abundantly clear how critical testing is to the overall success. It allows users to understand the application and confirm that business requirements are being met. It ensures system stability, scalability, and overall correctness of results.
One could easily conclude that more than 50% of all time and effort spent during an implementation project is spent on testing and testing-related activities. Choosing the right strategy for test data preparation for your project will decide the project's success and have a significant impact on duration, effort, and cost.
In this whitepaper, we will discuss different approaches used for test data preparation, their advantages and disadvantages, and our recommendation on when to apply which approach.
The approaches discussed in this document are
- Manual Preparation: Manual preparation of data by the testers
- External Data: Data delivered by an external system.
- Delete/Rerun: Reuse the exact previously delivered data.
- Data Copy: Creation of new data based on previously delivered data.
About the Author
Strategies
Manual Preparation
Manual preparation of test data involves creating or updating existing data to simulate specific business or compliance scenarios. It allows for the exact preparation of expected datasets to achieve the desired results. However, for that exact same reason, it is also the most unreliable dataset to be used for testing since it may not mirror actual production-like datasets. It also requires the most amount of application specific knowledge by the person preparing the data. Often, manual preparation is the only available option in the early phases of a project or the most effective way to produce specific datasets to test specific scenarios.
Pros:
- Manual data preparation is required when there is no existing data in the system.
- With manual test data preparation, we have full control of the data being used based on the business requirements or test scenario.
- Depending on testing needs, testers can create custom data specifically tailored to meet different use cases as required by business requirements.
- Mostly used during the prototyping and unit testing phase
Cons:
- Most time-consuming.
- The process of manual data preparation is prone to human errors and may lead to false test results.
- There could be inconsistencies in test results using multiple manually prepared datasets.
External Data
External data refers to leveraging the data prepared by upstream systems, such as policy management, commission, claims, and billing systems, which will be the source of information for regular production operations. It is the closest to production or, in some cases, maybe even real production data available for testing. It represents production regarding quality and volume and thus is crucial for use in system integration, performance, and user acceptance testing.
In the early stages of implementation, external data may not yet be available in the right quality or volume to test internal processes properly. Even as the integration matures, the availability of data from external systems may continue to be a challenge simply because production-like data is not available in the test landscape or due to necessary coordination efforts with external parties.
Finally, the same dataset cannot be consumed twice in FPSL, which means the external systems would require the capability to adjust the dataset for different test iterations in FPSL.
Pros:
- Production, like quality and volume, allows systems to perform under conditions closest to those that will be encountered in production.
Cons:
- Dependency on external sources may cause testing delays due to unavailability and coordination efforts.
- The inability to adjust external datasets for repeated test cycles may require lengthy or complicated deletion or client copy activities.
- The inability to filter external datasets may add a lot of unnecessary volume to the system, which will make it difficult to identify relevant test results and, over time, impact overall test system performance.
- Desired testing conditions may not be present in external data, or it may take additional time to identify the appropriate dataset.
- Failure to implement adequate security measures can lead to potential data security risks.
Deletion/Rerun
Deletion/Rerun refers to the ability to delete previously produced result data, thus allowing the system to reuse the exact same dataset for test re-execution. This may come in two flavors:
- Deletion of result data only, retaining the original source data (master data and flow data) and thus only re-executing the internal accounting processes
- Deletion of source and result data and re-executing a previous dataset, including the data load process from external.
This can greatly reduce data preparation efforts. Thus, it offers a very efficient way for unit testing or certain functional tests. However, there is no out-of-the-box deletion process available. Custom deletion processes delete most relevant data, but not all data, and are not officially supported. Accordingly, they should not be leveraged for the final sign-off of regression or user acceptance tests.
Pros:
- Greatly reduced data preparation effort
- Enables re-use of external datasets without the need for adjustments.
Cons:
- Previous test results are deleted, and it is not possible to retain or compare them to previous test executions.
- Deletion is not officially supported, and use is at its own risk and should not be used as a final result for regression or UAT.
- Deletion is not officially supported, and the same process may not be applicable to all customers and may have to be adjusted in future releases.
Data Copy
Data copy is the ability to copy relevant information from existing data that was already created. The process includes copying data within or from an existing source, such as legal entity, source systems, portfolios, contracts, etc., to eliminate the need for and time spent creating data from scratch.
The copied datasets provide a baseline of information and a foundation for testing and validation of the FPSL systems. In addition to copying datasets, some modifications are required to ensure that the newly created data meets additional data scenarios to cover various testing phases, such as user acceptance testing, regression testing, and performance testing.
This helps to identify any issues and ensures the systems are performing and functioning as expected.
Pros:
- Data copy with required parameters makes it easy to validate data integrity and consistency at the legal entity, company code, and GL account level.
- The data copy allows efficient regression testing. It’s much easier to identify any system issues when you use the same dataset across different testing cycles.
- The automated feature helps reduce errors associated with manual processes.
- It helps reduce the time and effort required to build data from scratch.
- Normally used during system testing, performance testing, regression testing, and user acceptance testing phases.
Cons:
- With multiple data copies, there could be significant storage issues, which may invariably impact the system's performance.
- The test system becomes cluttered with unnecessary data, which may slow/ degrade the performance.
- It may be expensive to set up in the first place.
Volume Consideration
An important factor when evaluating test strategies for various project phases is volume consideration. The goal is to strike a balance between creating production-like datasets and testing effectiveness. While it is great to utilize production-like data during System Integration Testing (SIT) for logical representativity, it is crucial to exercise caution.
Often, Customers frequently encounter problems relating to high data volumes or dealing with data interfaces from external sources, where millions of records are involved, making it a challenge to efficiently identify and address any potential issues or root causes. While performance challenges are eventually overcome, it is advisable to adopt a phased approach rather than immediately burdening the system with a large dataset. While the temptation to test the entire functionality at once may exist, it is important to acknowledge that testing is an iterative process. Therefore, a step-by-step increase in volume, coupled with a focus on integration aspects during SIT, proves to be a more effective strategy.
The reasoning behind this caution lies in the potential for encountering performance bottlenecks if the full production volume is introduced too early. Therefore, it is essential to prioritize reduced representative data and focus on evaluating actual functionality rather than system performance resulting from large data, especially during the early SIT phase of testing.
Choosing a Strategy
When it comes to choosing the right strategy for test data preparation, one must weigh several factors. If it were only about ensuring accurate test results, then using comprehensive production data would always be the best approach, however, this would also be extremely cost-prohibitive since tests with the exact same dataset cannot simply be repeated and, due to data volumes, can be extremely time-consuming.
Data Quality measures the accuracy of datasets compared to production data and will ensure the accuracy of test results and overall test coverage as it pertains to the data's diversity.
Risk Reduction measures the effectiveness of the approach regarding delivering false positives/negatives not related to data quality itself but the overall test coverage. E.g.: Leveraging external minimizes the overall risk since it extends the test coverage across all applications, as well as the integration layer itself, which typically contains additional transformation rules.
Cost Reduction measures the overall effectiveness of the approach allowing tests to be performed in less time, with less effort and less expertise required.
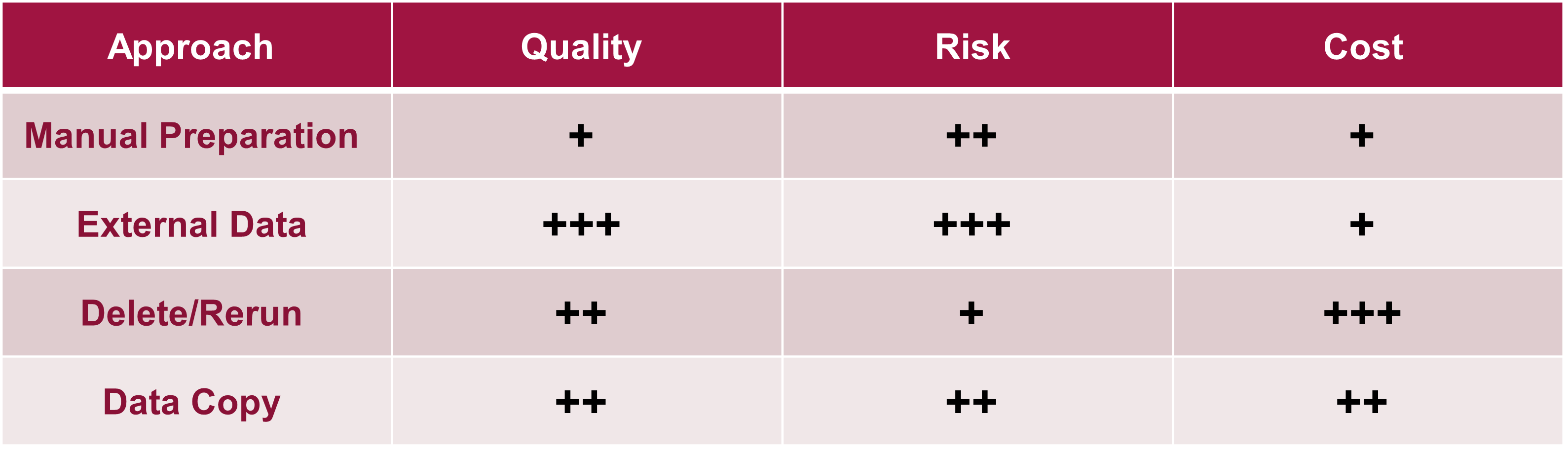
Customers cannot rely on only one approach for all their testing needs. The key to success is applying the right approach for the right test cycle to maximize effectiveness and minimize cost.
Test Cycles
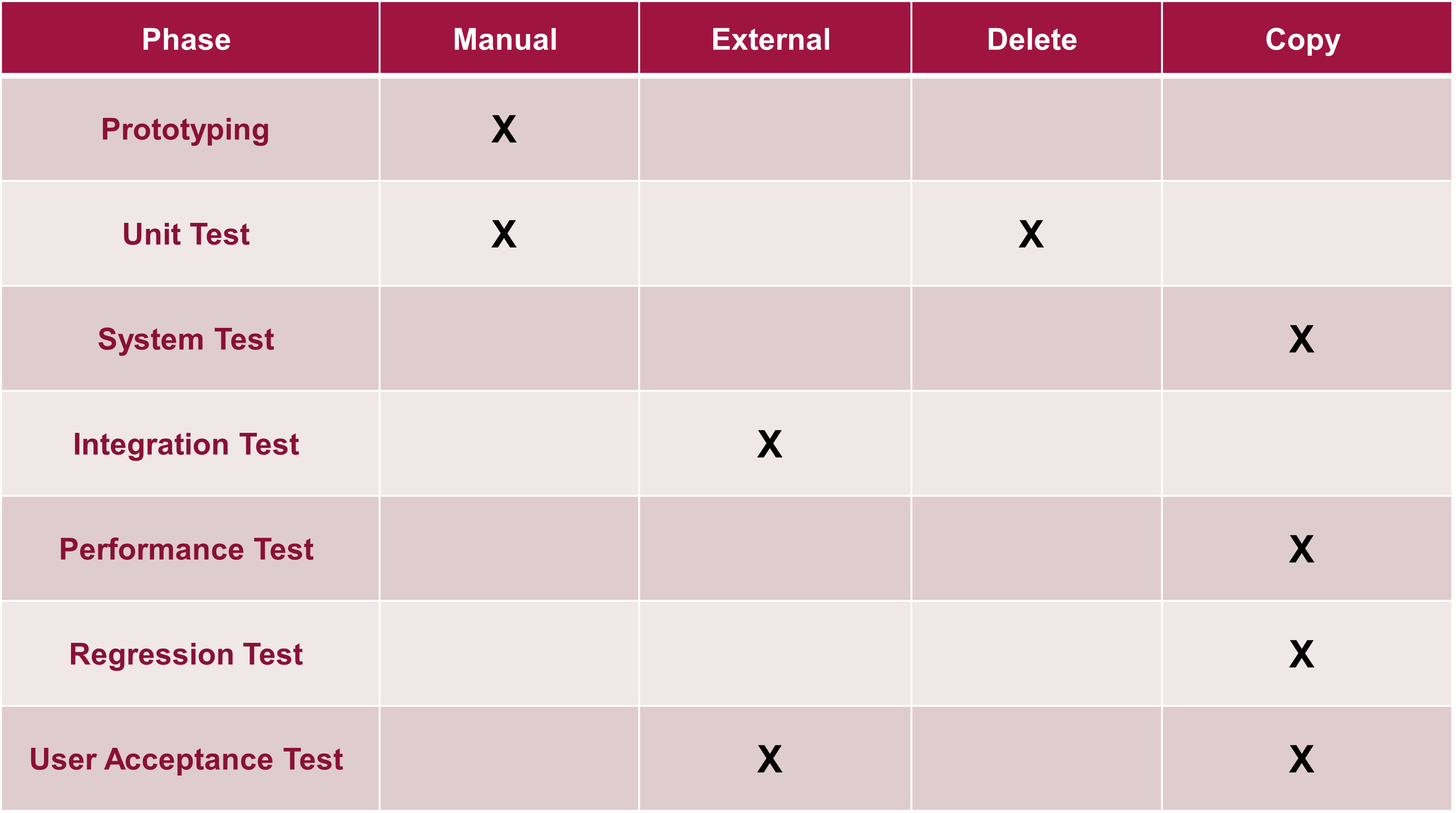
Prototyping is usually performed during the early phases of the project or when the team is experimenting with new features and functionality to explain the application or to determine if a certain functionality is applicable to the final solution. Since test data is rarely available at the prototyping stage, data typically must be manually prepared or at least partially adjusted to meet the new system requirements.
Unit Testing is performed in a development system when a new functionality has been completely developed, a configuration change has been performed, or a defect has been resolved. The purpose of unit testing is for the developer to ensure that one specific feature or functionality is working as intended under extremely limited circumstances with a limited number of scenarios to be covered. Since additional test cycles typically follow a unit test, volumes are typically very low, and a delete/rerun approach is recommended for a maximum reduction in processing time.
System Testing is performed in a quality environment to ensure that all business functions are working as expected and that all business requirements are met. System testing requires the most comprehensive dataset to ensure every data permutation is tested. To accurately test all system functionality in a reliable fashion data copy approach is recommended. A representative dataset regarding complexity yet reduced in volume in comparison to production should be leveraged to maximize the effectiveness and reduce overhead on the system, especially if multiple test cycles are required.
Integration Testing is performed in the quality environment to ensure the data flow is working correctly between all applications involved, including validations, substitutions, and all data mappings between the applications. It requires close coordination between the respective teams responsible for each application. Given the nature of the system integration test, the data must be prepared externally. A representative dataset in regard to complexity yet reduced in volume in comparison to production should be leveraged to maximize the effectiveness and reduce overhead on the system, especially if multiple test cycles are required.
Performance Testing checks how a system performs under a particular workload. It measures attributes like speed, scalability, stability, resource utilization, and responsiveness. The goal is to identify and eliminate performance bottlenecks to ensure the software meets the required performance criteria. The key to successfully testing & tuning system performance is the availability of multiple sets of test data that can be processed in quick succession after performance optimizations have been performed. Data copy is the preferred approach for performance testing and production, where volumes should be leveraged. If production like volume is not available, a copy tool would also offer the ability to multiply the data.
Regression Testing ensures that previously developed and tested functionality still performs the same way after it is modified to avoid unintentional side effects. It's crucial because it helps detect bugs that may have been introduced into the system during the integration of new features or functionality, ensuring the software's reliability and stability. Due to the nature of regression testing, trying to validate predictable pre-defined outcomes based on a stable pre-defined input data copy is the best approach. A representative dataset regarding complexity yet reduced in volume should be leveraged to maximize the effectiveness and reduce overhead on the system, especially since regression tests are repeated after any significant change in the system.
User Acceptance Testing is the final phase in the software testing process, where actual software users test the software to ensure it meets their requirements. It is performed after system testing and before product launch. The scope includes validating end-to-end business flow and real user scenarios. UAT is performed by the intended users of the software, often clients or end-users, to ensure the software can handle required tasks in real-world scenarios, as per their needs. While externally prepared data cannot be avoided for initial implementation since the user must provide sign-off on the integration itself, for later releases, a data copy approach may be acceptable.
msg Tools
Considering the above test strategies and based on our vast experience with SAP implementations across many geographies, msg global has developed msg global Adjustment and Error Handling Framework (AEF) to streamline the test data preparation process. With our tools, we are helping our clients reduce test duration, improve quality, detect issues early, and reduce costs.
Manual Preparation
Depending on the organization's testing approach, testing tools can be used to automate the data preparation process, thereby improving and streamlining testing efficiency while validating system responses.
Leveraging msg global Adjustment and Error Handling Framework enables effortless data uploads to multiple interfaces with just a single button click. The advanced import feature automatically removes common data issues encountered with manually prepared data, such as adding leading zeros, removing special characters, and handling date and currency issues. Given its full integration into SAP S/4 HANA, the application directly accesses the SAP data dictionary, automatically validating foreign key relationships and domain values.
The sophisticated workflow of the system automatically notifies users of any import issues through email alerts and guides them through the correction procedure, ensuring additional review and complete traceability of any manual changes. This thorough approach supports the auditability of the system.
The msg global Adjustment and Error Handling Framework enhances the FPSL manual data entry process, minimizing errors and improving the overall quality of data.
To efficiently handle data related to the Reconciliation Sheet for Actuarial Portfolio Definition, Portfolio Assignment, Best Estimated Cash Flow (BECF), and Exposure Period Split (EPS), the tool follows a structured sequence of steps.
- Excel Template with required test data
- Upload Data
- Data Correction & Workflow
- Dependencies
- Configuration
Manual data preparation, whether for monthly, quarterly, or annual bulk uploads, can be seamlessly executed in the background within seconds. And if any data issues arise, a triggered workflow facilitates efficient data correction.
The tool handles tasks such as processing Portfolio definitions, loading analytical statuses, and managing Portfolio assignments.
With over 69 predefined configuration validations, the application covers a comprehensive range of scenarios, including FPSL GL coding for all typical situations.
In Test Data Management (TDM) options, there is the capability to map rules to individual interfaces that they apply, ensuring consistent application of all validations and substitutions across all interfaces.
msg Adjustment and Error Handling Framework can streamline and improve the data quality of manual data input for all SAP FPSL implementations.
Deletion/Rerun
In many SAP FPSL implementations, clients often require the ability to re-run accounting results for validation purposes.
The msg Test Suite for FPSL enables a rapid re-execution of test results, providing a quick turnaround for business user validation.
The tool can selectively delete results data, including Sub Ledger Posting Documents (SLPD), Target Values (TVE), etc., as well as trigger tables data, without impacting the source data (FT, BT, BECF, etc.). If source data is available, accounting processes can be reprocessed to evaluate the results.
Certain source data tables play a crucial role in calculating sub ledger results. The approach involves keeping all the sources, deleting calculation tables along with the sub ledger table, and subsequently re-creating triggers by reusing the data.
This tool includes the following features:
- Delete the entire dataset or by key date
- Delete ECP (ACG, BECF, EPS)
- Delete Accounting (SLPD, TVE)
- Based on volume, provide parallel processing parameter
You can apply a combination of copy/delete. Considering the significant amount of time required for loading the new data, it is practical to conduct a retest by deleting it first. Once satisfied with the outcomes and have obtained final confirmation, the next step is to load new data.
Two copy/delete approaches are available: one for deleting all entries and another exclusively for deleting accounting records.
Deleting all entries approach will trigger the following sequence of events.
- After creating the register entries.
- Delete the entries created by ECP (BECF, EPS) that were created the first time.
- Delete the calculation results (Earning Percentage, Target Values).
- Delete the Subledger results.
- Now, we can recreate the triggers for validation.
The delete accounting ONLY approach will trigger the following sequence of events for any system/accounting configuration changes.
- After creating the register entries.
- Delete the accounting results only.
- Keep the calculation results (Earning Percentage, Target Values).
- Keep ECP (BECF, EPS) results.
- And recreate the triggers so the system recalculates.
Data deletion/ Re-Run capability helps clients save time and effort if there is no change/issue with the source data.
Data Copy
For Data Copy, we leverage msg Copy Tool for FPSL along with msg Adjustment & Error Handling Framework. This combination facilitates seamless data transfer across legal entities, as well as utilizing the copy tool to create data for the remaining year utilizing the date increment option.
In SAP Financial Product Subledger (FPSL) test validation typically occurs at legal entity level, it is common practice to reload the data under a new legal entity to re-execute a test case. However, reloading the data is not always that easy and may not be supported by the integration layer. Additionally, when assigning data to a new legal entity, portfolio, and contract IDs, adjustments are required.
This tool supports the following features
- Copy Tool
- Increment Dates
- Parallel Processing
Specify the legal entity to copy, provide all parameters required in the tool for Legal entity, Source system, Portfolio definition, Portfolio assignment, Analytical status, Best Estimated cashflow, Exposure period split. This tool can also be used to configure more applications in the future based on specific client needs.
By providing parameters for test data preparation and initiating the data copy process, the tool efficiently completes the entire copy operation within seconds, allowing more time for thorough result validation. Validate data in respective tables with the new legal entity to ensure accuracy.
The Copy feature in the Copy tool provides various options for duplication, such as a basic copy, simulation for new business, cashflow, and export option. Moreover, this tool enables users to copy data incrementally on a monthly or quarterly basis. Additionally, it allows users to copy data in for Contract and Portfolio ID when creating new data, which enhances efficiency by facilitating parallel processing. The utilization of parallel processing facilitates simulation of production volume for generating test data in the test environment.
About msg global solutions
msg global solutions is a systems integrator, software development partner, and managed services provider focused on SAP solutions for multiple industries. Our services include strategies for accounting, finance, regulatory reporting, performance management, sustainability, customer experience, and IoT. Operating from offices across the globe and growing, our expert teams help clients achieve operational efficiency and improve decision-making capabilities.
At msg global solutions, we strive to provide best-in-class implementation services and continuously improve our delivery methodologies and best practices to ensure the greatest possible results with the lowest possible total cost of ownership and help our customers maximize the value they get from their SAP investments.

About the Author
Jan Bornholdt | Director, msg global solutions
Jan Bornholdt is a director at msg global solutions inc. As an SAP for Insurance Subledger expert, he has worked with various sub-ledger technologies for over 20 years. In his career, Jan has helped dozens of clients successfully integrate SAP sub-ledger technologies in their overall financial system landscape.